
2022. 2. 14. 00:00ㆍUX 아티클 ✏️/③ UX 라이팅

데이터 드리븐 UX Writer는 어떻게 될까? Writing의 A/B 테스트는 어떻게 하지?
Patrick Stafford의 [How to become a data-driven UX writer (and how to A/B test copy)]의 번역본입니다.
How to become a data-driven UX writer (and how to A/B test copy)
How does data-driven decision making work? How can you, as a writer, incorporate data?
medium.com
데이터에 대한 지식은 개발이나 프로덕트 매니지먼트 같은 기술적인 분야로 집중되는 경향이 있습니다.
라이터 (Writer)에 대해 얘기할 때, 데이터 기반의 의사결정은 조금 미지의 영역이기도 하죠. Writer로서 당신의 프로덕트에 어떻게 데이터를 적용해갈까요? 그뿐만 아니라 페이지의 다른 요소와는 별개로 어떻게 문구(Copy)에 미치는 영향을 테스트할 수 있을까요?
데이터를 이해하고, 문구의 A/B테스트를 진행하고, 데이터를 기반으로 의사 결정할 수 있는 UX Writer와 콘텐츠 전략가는 큰 경쟁력을 가질 수 있을 거예요. 하지만, 생각을 약간은 바꿔야 할 수도 있죠..
The data-driven process
데이터 드리븐 프로세스를 라이팅 (Writing)에 어떻게 적용하는지에 대해 논의하기에 앞서, 이 용어 자체에 대해 먼저 얘기해보고자 합니다. 데이터 드리븐 (data-driven)의 실제 의미는 무엇일까요?
<데이터 드리븐>을 한다는 것은 수치, 템플렛, 차트에 대한 거라기 보단, 구체적인 결론을 가져다 줄 멘탈모델에 가깝습니다. 데이터 기반의 결정을 내려야 할 때 스스로에게 질문해 보세요.
1) 당신이 답하고자 하는 질문과 관련된 주된 콘텐츠는 무엇인가요?
당신의 디자인 도전의 실제 목표는 무엇인가요? 이건 어렵지 않습니다. 디자이너나 라이터(Writer)가 항상 하는 거니까요.
2) 어떤 데이터가 질문에 답하는데 도움을 줄까요?
이 질문은 현재 문제에 대한 답을 찾는데 도움을 줄 데이터에 집중하는데 도와주고, 특정한 목적 없이 데이터를 수집하기 위해서만 데이터를 계속 모으는 data creep이 되는 걸 막아줍니다.
3) 어떤 데이터가 불완전할까요?
당신의 데이터셋에서 어떤 걸 놓치고 있는지 생각해보세요. 놓치고 있는 데이터들이 당신의 데이터를 망치고 있나요?
4) 그 데이터 자체만으로 당신에게 설명해 주는 건 무엇인가요?
다른 것들과 관련짓지 않았을 때 데이터 그 자체가 무엇을 말해주나요? 예를 들어, 히트맵은 사람들의 50%만이 특정한 지점 너머로 스크롤한다는 걸 보여줄 것입니다. 이건 당신에게 ‘왜'를 말해주진 않습니다.
5) 그 데이터를 신뢰할 수 있나요?
믿을만한 가치가 있는 자료인가요? 출처는 어디인가요?
6) 다른 데이터가 제공하지 않는 어떤 콘텍스트를 그 데이터가 제공하고 있나요?
이 질문은 데이터가 작동하는 것은 당신이 그걸 필요할 때면 언제든 정보를 잡는 것은 아니리는 것을 보여줍니다. 그건 적정한 문제를 위해 올바른 데이터를 적정 시간에 잘 따르기 위한 프로세스입니다.
어떻게 데이터 드리븐 접근법을
Writing에 적용할 수 있을까요?
더 많은 UX라이터 (UX Writer)들이 데이터로 일하면 일할 수록, 위 질문은 무의미해지지만, 어떻게 UX라이터들이 그들의 프로세스에 데이터를 포함할 수 있을지에 대한 질문으로 남게 됩니다.
살짝 질문에서 떨어져서, UX라이터들은 디자인 문제를 해결하는 데 있어서 사용할 수 있는 데이터가 많다는 것을 인식해야만 합니다. 예를 들어, 데이터는 이런 곳들로부터 수집될 수 있습니다.
- 유저 테스트 세션
- 인터뷰
- 원격 측정 (실제 사용자들이 당신의 프로덕트에서 무엇을 하는지)
- 카드 소팅 활동
- 히트맵
- 스크린 기록
- 아이 트래킹
- A/B 테스트 결과
다시 본 질문으로 돌아와서, 그렇다면 라이터들은 어떻게 그들의 프로세스에 데이터를 적용할 수 있을까요?
어떻게 문구 A/B테스트를 진행할까?
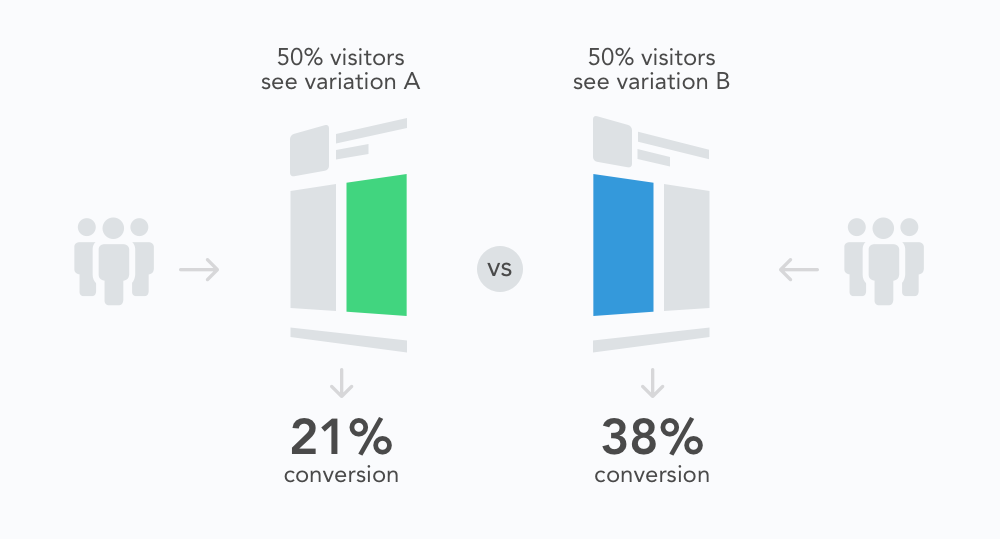
이 과정에 대해 말하는 것은 가능한 한 더 많은 맥락에서 도움이 됩니다. UX라이터나 콘텐츠 전략가에게 많은 양의 데이터가 포함된 프로젝트 중 하나는 A/B테스트입니다. 이런 맥락에서 데이터 드리븐 멘탈 모델에 대해 이야기해보겠습니다.
A/B테스트를 하고자 하는 목적은 무엇인가?
A/B테스트는 한 버전이 다른 버전보다 더 나은지를 판단하기 위해 설계됩니다. 예를 들어, 우리가 시리얼 회사에서 일하고 있고, 새로운 문구를 테스트하고자 한다고 상상해봅시다. 우리는 전환율 상승이라는 목표를 지니고 있습니다. 이 목표가 우리는 시작점입니다.
어떤 데이터가 우리 문제와 관련이 있을까?
우리의 버전 2를 판단할 수 있는 모든 데이터를 생각해보자. 기억하세요. 어떤 데이터가 원인에 가장 가까운지를 판단하는 것이지 수집할 가능성이 있는 데이터를 사용하는 것이 아닙니다.
우리는 히트맵, 사용자 조사, 이전의 A/B테스트, 트래픽과 전환 데이터로 시작할 수 있습니다.
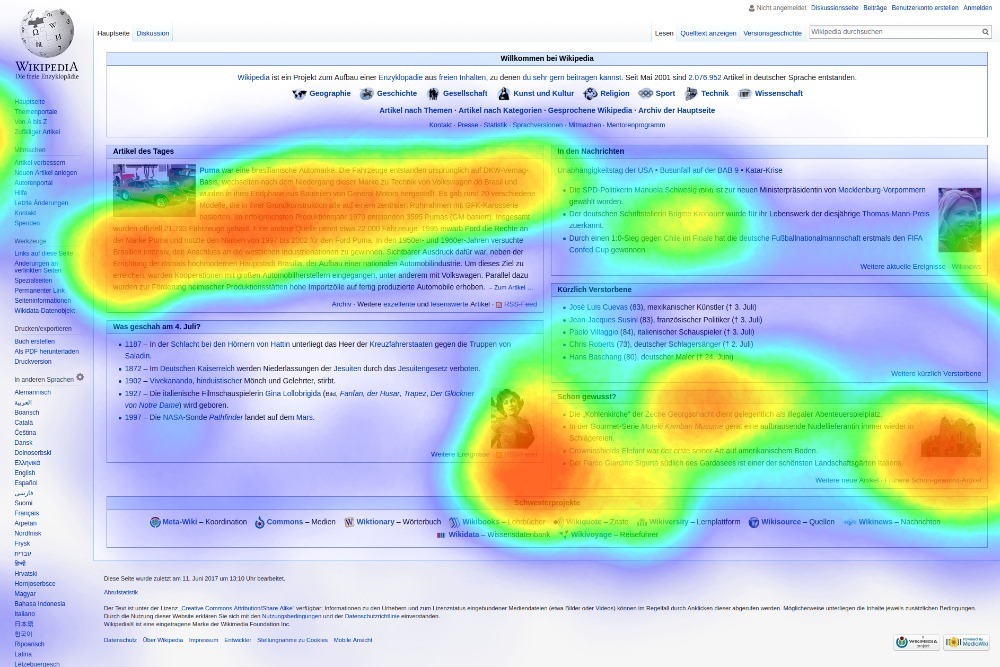

히트맵 (Heatmaps)
본 페이지에서 어떻게 사용자가 기여하는지를 보여줍니다.
사용자 조사
만약 해당 페이지를 직접 테스트한다면, 비록 질적 연구는 아니지만 정성적인 연구로 돌아가서 왜 사용자가 그렇게 행동하고, 행동하지 않는지를 이해할 수 있습니다.
이전의 A/B테스트
이 페이지에 이전 A/B 테스트가 5개 있다고 가정해 보겠습니다. 특히 문구가 포함된 테스트였다면, 어떤 근거로 사용자들이 읽지 않는지를 확실히 설명할 수 있어야 합니다.
트래픽과 전환 데이터
3달간의 데이터를 통해 우리는 다른 페이지와 비교해서 해당 페이지가 어떻게 작동되는지를 알 수 있습니다.
이 데이터의 한계를 무엇일까요? 어떤 데이터를 놓치고 있을까요?
첫 번째 원칙을 기억하세요. 각 정보가 그것 스스로 무엇을 말하고 있나요? 우리는 다른 것이 아니라 눈앞의 정보로 무엇을 얻을 수 있을까요?

히트맵 (Heatmaps)
이 지도는 사용자 중 25%만이 아무런 행동을 하지 않은 기본 화면(Fold)을 넘어서서 스크롤한다는 것을 보여줍니다.
이전의 A/B테스트
이 테스트는 긴 것보다 짧은 페이지가 더 많은 사용자가 전환되었다는 것을 보여줍니다.
트래픽과 전환 데이터
과거 3달 동안 Organic traffic(광고에 영향받지 않고 서비스에 유입한 것)이 감소했고, 전환율 또한 10% 감소했다.
데이터는 우리에게 무엇을 말해주고 있을까요? ‘왜’에 대한 것은 추론입니다. 사용자가 짧은 페이지를 더 선호한다고 말할 수는 있지만, 항상 사실은 아닙니다. 우리가 아는 건 사용자가 짧은 페이지에서 더 잘 전환한다는 거죠. 이건 같은 건 아닙니다.
데이터 드리븐 멘탈모델을 사용한다는 것은 당신이 아는 것과 모르는 것에 대해 더 구체화한다는 걸 뜻합니다. 당신이 알다시피, 우리는 특정한 데이터를 놓치고 있습니다. 우린 각 버전의 페이지마다 사용자가 구체적으로 어떤 걸 더 좋아하는지에 대해 말하는 인터뷰를 갖고 있지 않으니까요. (그저 전환 데이터와 수치만 갖고 있죠)
데이터를 시각화하기 위한
매트릭스 만들기
모든 정보를 생각하는 건 혼란을 줄 수 있습니다. 당신이 알고, 모르는 것을 매트릭스에 배치해보세요.

가설을 세우고, 테스트 만들기
우리의 정보가 정리되었으니, 우리는 가설을 세울 수 있습니다. 사람들이 방문하지 않거나 전환되지 않는 데에는 여러 가지 이유가 있을 수 있고, A/B 검사를 통해 의심이 가는 이유를 찾아낼 수 있습니다.
중요한 부분은 이 멘탈 모델링 과정을 겪었기 때문에 당신이 만든 어떤 가설도 신뢰할 수 있는 정보에 기초한다는 것입니다.
누군가가 당신이 만든 가설을 비판할 수 있을지도 모르지만, 적어도 그 가설은 사실에 기반을 두고 있습니다. 그것이 좋은 UX 라이터와 데이터를 통합하는 방법을 이해한 위대한 라이터들 사이의 차이점입니다.
연습은 완벽함을 만듭니다!
이것은 하룻밤 사이에 배울 수 있는 것이 아니며, 문구(copy) AB 테스트 방법을 배우는 것은 예시일 뿐입니다. 완전히 새로운 온라인 흐름을 만들거나 앱에서 새 화면을 만들거나 완전히 새로운 전자 메일 시리즈를 만들 때도 동일한 원리가 적용됩니다.
Writing에서 데이터 기반 프로세스를 사용하려면 시간이 걸리지만, 올바르게 수행하는 것이 중요합니다.
코딩을 배울 필요는 없고, 생각을 바꾸면 됩니다. 일단 그렇게 하면, 당신은 이길 수 없는 경쟁 우위를 갖게 될 것입니다.
Patrick Stafford의 [How to become a data-driven UX writer (and how to A/B test copy)]의 번역본입니다.
How to become a data-driven UX writer (and how to A/B test copy)
How does data-driven decision making work? How can you, as a writer, incorporate data?
medium.com

'UX 아티클 ✏️ > ③ UX 라이팅' 카테고리의 다른 글
| [UX Writing] UX 라이팅 두가지로 요약해드립니다. - ❷편. 맥락에 따라 일관된 성격으로 말걸기 (0) | 2023.09.18 |
|---|---|
| [UX Writing] Q: UX 라이팅 어떻게 써야할까요? A: 두가지로 요약해드립니다. - ❶편. 이해하기 쉽게 쓰기 (1) | 2023.07.28 |
| [UX Writing] 개념 뽀개기 (UX 라이팅, UX 디자인, 마이크로카피, 카피 라이팅, 테크니컬 라이팅, 콘텐츠 전략 뭐가 다른데??) (2) | 2023.07.28 |
| [UX Writing] 02_없으면 안되는 내용에만 집중하기 (0) | 2022.01.12 |
| [UX Writing] 01_없으면 안되는 내용에만 집중하기 (0) | 2022.01.06 |
